The internet: a short primer
November 16, 2017
I recently went back to my old bootcamp, Founders and Coders, to give an alumni talk on The Internet.
Bootcamps have the difficult task of condensing an immense amount of information into a short space of time. The focus is on getting people to the stage where they can be productive developers. Inevitably this means that some topics get delegated to the “you’ll pick this up along the way” category. At Founders & Coders we use Heroku for deployment in order to abstract away the infrastructure details and allow students to focus on their development skills.
Of course, this doesn’t entirely do away with the need to use and understand things like IP addresses, port numbers and so on, but these aren’t explicitly explained. And eventually students will need to be able to deploy their work without using Heroku.
So I decided to give a talk covering the basics of computer networking that would be useful for bootcamp students. While giving the talk I realised I’d been a bit ambitious in how much I could reasonably cover in the time, so the purpose of this post is to go over things in slightly slower time.
I hope to show that things like Heroku and the internet itself are wonderful abstractions, but we needn’t be afraid to look under the hood at how these abstractions work.
What is a network?
Computers can be connected together in a network. This means that the computers are able to share data in some way. Lots of businesses have a corporate intranet, accessible only to computers on their network, allowing them to access documents on shared drives and so on.
But what if you want to communicate with a computer not on the network, such as Google’s search server?
Well, perhaps there’s no direct link between your computer and Google’s, but a machine on your network is connected to another network and a third machine in that network is connected to Google’s server. By sending your message out of your network and through the other you can communicate indirectly with Google’s server.
Talking to machines in your network is ‘intra-network communication’, hence the term ‘intranet’. Talking to machines across networks is ‘inter-network communication’, hence the ‘internet’. The internet is just a network of networks, allowing communication between machines that aren’t directly connected.
The internet
Communication over this network of networks happens using a series of nested networking conventions (known as protocols). Normally they’re represented as a stack of layers, so you might come across the term ’networking stack’, but I’m going to use Russian dolls as I think they better convey the idea of messages wrapped in messages.
The innermost doll represents the actual message you want to send - perhaps an HTTP request to a web server. That gets wrapped inside a Transmission Control Protocol (TCP). That message in turn gets wrapped in an Internet Protocol (IP) message. There are further layers involved in physically sending the information over wifi or ethernet, but I won’t go into that here.
When the server receives the IP message it will strip off the various layers to get at the original message in the middle.
Internet Protocol

The Internet Protocol is responsible for getting data to the correct destination. Each machine on the internet is allocated an IP address. You can think of this as the postal address of the machine. Any other machine can send a message to your machine by sending a message addressed to its IP address.
Whenever you want to send a message over the internet (e.g. an email, a web request, whatever really) your operating system is responsible for breaking that message down into a series of packets, each addressed to the destination’s IP address. These packets get fired off to the next step on your computer’s network, which is most likely a router belonging to your internet service provider (ISP).
Routers are computers designed to be good at processing lots of internet requests very quickly. They maintain large lists of IP addresses they know how to connect to. When your request hits the server it’ll look at the request IP address on the packets and forward it on. If the router doesn’t have a direct link to the destination it’ll try to pass it on at least part of the way. Each packet has a number recording how many more hops it’s allowed to make. Once this number (the ’time to live’) hits zero the packet is dropped by the router. This stops packets getting stuck in an endless loop of routers and never leaving the network.
You can see the route taken by packets across the internet by using a tracerouter like mtr.
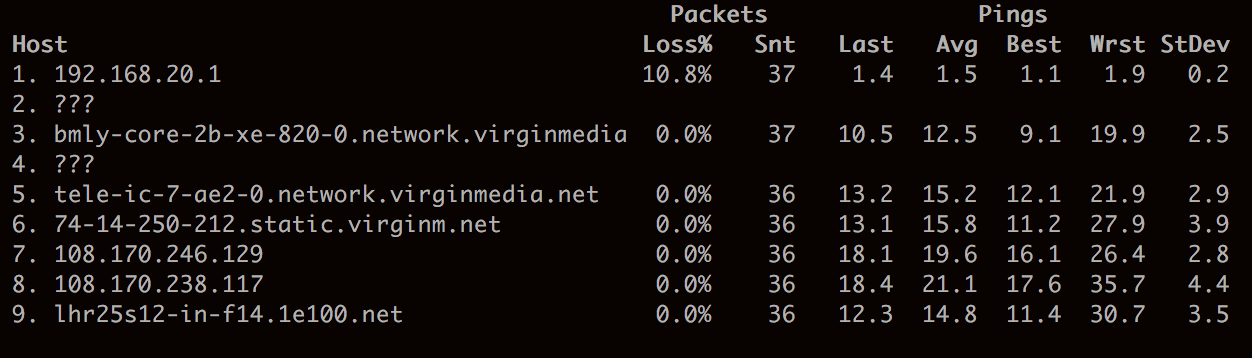
From the point of view of your sending computer, all it knows that it has sent off a particular number of packets to a destination. It has no knowledge of what actually happens on the network. In particular, it doesn’t know if all of the packets arrived. For this reason IP is known as an unreliable protocol. The computer on the receiving end will get any packets that find their way successfully across the network, but it has no way of knowing if any got lost along the way or if they have arrived in the correct order.
As you can imagine, this presents difficulties. How can the receiver reconstruct the message if it doesn’t know how many packets it should have received and in what order?
Transmission Control Protocol

To solve these problems we use another protocol, the Transmission Control Protocol (TCP). This protocol adds extra information, most importantly a packet’s position in the overall transmission (e.g. tenth out of fifty).
When the receiving machine strips off the outer IP layer of the packet it can use the information provided by the TCP layer to put the received packets back into the order in which they were sent. If any are missing it can ask the sending machine to resend the missing packets.
We now have the concept of a connection - data going back and forth between sender and receiver - and a guarantee of reliability.
The key thing to note is that these features are built on top of the Internet Protocol. In this way we are building the abstraction of a reliable connection on top of something that fundamentally lacks both the concepts of a connection and reliability.
In practice these features are so useful that TCP and IP are nearly always used together and are known as the ‘internet protocol suite’, or TCP/IP.
Sadly, the benefits of TCP don’t come for free. At the IP layer your machine can just spit out as many IP packets as the hardware will allow and hope for the best. At the TCP layer it has to negotiate a connection with the receiver, which involves a couple of trips back and forth before any actual data can be sent. The receiver has to keep track of what it’s received, put them in the right order and deal with missing packets. Thisall adds overhead.
Since neither the sender nor the receiver knows anything about the network in between, they have to start off each TCP connection by sending packets at a slow rate and gradualy ramping up from there. Unfortunately this ramp up happens every time a new connection is made, even between the same two machines. Creating a new TCP connection is also therefore relatively expensive.
Ports
So we’ve managed to successfully deliver our full message to the correct machine using a combination of TCP and IP. But what is our actual message and how can the receiving computer read it? From the point of the TCP/IP stack the message is just a series of bytes. It doesn’t understand or care about what the message contains. So how can the receiver know what the bytes are meant to signify?
What we need is some kind of agreed protocol by which the sender and receiver can agree on how to encode and decode their messages and some way of indicating which protocol is to be used. This is where ports come in.
Each TCP packet is addressed to a particular port on the destination computer. By convention, different ports are assigned to applications using particular protocols. The operating system is responsible for stripping off the IP and TCP layers from packets it receives and passing the application data to the correct port.
For example, a web server will listen to port 80 and expect to receive HTTP messages. A file-transfer server might listen on port 20 and will expect to get messages in the FTP protocol.
There’s nothing stopping us from sending an FTP message to port 80 on a server, but the server will almost certainly try (and fail) to interpret it as an HTTP request because that’s what conventionally is sent on port 80.
The best analogy I can think of is that ports are like the rows of letterboxes you find inside the entrance of large apartment blocks. The IP address is the physical address of the building. Every apartment in the block therefore shares the same address but post can be delivered to the correct apartment by inspecting the apartment number on the envelope and placing the item in the correct letterbox.
On Unix-style systems, by the way, a port is implemented as a socket, a type of file descriptor. Programs can read and write from them just as they would with a normal file. But rather than communicating with the computer’s hard drive we communicate with another machine out on the internet. This is another example of abstraction.
The web

Once we take off the wrapping of the TCP layer, we are left with the actual application data, hopefully delivered to the correct port by the operating system. Ports numbered below 1024 are designated ‘well-known’ ports and have an assigned protocol. You can see a list here.
As you can see, the web is just another application using a designated port and protocol (HTTP over port 80).
Any time we make a browser request we are actually sending an HTTP request to port 80 on the server. Because it’s expecting to receive HTTP requests on that port it can correctly parse our request and provide the appropriate response.
What is a web server?
One thing that I used to find very confusing was the term ‘server’ itself. People called intense-looking machines in datacentres ‘servers’ but then they also talked about writing servers. If I could write a web server in node.js then how did it differ from something like Apache, which called itself a ‘HTTP server’?
As you probably guessed, these are all servers. The confusion arises because the word ‘server’ means slighly different things at different stages in the request’s lifetime.
Hardware server
These are both servers:

Any computer with an internet connection can be a server. Some, like the ones on the left, are optimised to deal with many concurrent connections. But that’s it really.
HTTP server
Programs such as Apache and nginx are known as HTTP servers. Rather than having a node.js or Ruby on Rails application listening directly on port 80, it’s usual to have something like Apache sit between. The two main reasons for this are speed and security.
First of all, speed. Many HTTP requests are for static resources such as images, HTML files and CSS. Apache and other HTTP servers are designed to do this much more quickly, and under a much higher concurrent load, than an application written in JavaScript or Ruby could handle.
Secondly, ‘well-known’ ports (those numbered below 1024) can only be listened to by a root process. While you could simply run your node.js app with sudo and listen directly to port 80, this is seen as a bit of a security risk because you’re allowing a root process to have open access to the internet. HTTP servers usually have functionality to mitigate this risk, such as starting as root before dropping down to a less privileged user.
Web app
A server written in node.js or Ruby on Rails is perhaps better known as a ‘web application’. This is because it’s not simply serving static assets but can execute any kind of code you want in response to a request. Image processing, reading and writing from a database, whatever you want.
Here we can see another layer of abstraction developing. IP gives us the abstraction of communicating across networks as if they were one network. TCP gives us the abstraction of a reliable communication with another computer. HTTP gives us a simple abstraction for reading resources (i.e. files) from another computer. Now, with the rise of web apps, we are developing an abstraction for executing code on another computer. The data we pass in the request, in the form data or query parameters, act like arguments to a function that’s executing on the server. The return value is sent back to us in the resstatus code and body of the response.
I find this distinction helpful for when thinking about how HTTP servers work with web apps: the server handles fetching resources, the app handles executing code.
What if you want to do something more sophisticated, such as talking to a database? The HTTP server can forward such requests on to a web app running on a different port. This is why our node.js apps normally listen on a high port (e.g. 9000). Our node.js app doesn’t actually talk directly to the internet. Apache will receive a request on port 80 and forward it to port 9000. The web app will hear the request on port 9000 and do whatever activity is required. It’ll write its response back into port 9000, which will be picked up by Apache and written out to the client via the server’s port 80.
Heroku
Armed with this knowledge we are ready to pull back the curtain on what Heroku does. It is a ‘platform as a service’ (PaaS), meaning that it abstracts away all of the infrastructure details. We don’t need to worry about what machines our web app is running on or how it’s connected to the internet. We just need to drop in the final element, our web app itself.
But how does a node.js web app, running on a server on a high port like 9000, actually communicate over HTTP with the outside world on port 80?
The web app doesn’t actually talk directly to the internet. When an HTTP request comes in, the first thing it hits a HTTP server like Apache. It’ll forward the request on by opening a connection to the web app’s port (let’s say 9000 in this example) and writing the request into it. The web app reads the request from port 9000, does whatever work is needed and then writes its response back to port 9000. Apache then reads that response from port 9000 and writes it back out to the original client via port 80.
You can find a small node.js project demoing this here. A web app running on port 9000 is able to handle requests on port 80 by having them forwarded by the code in server.js (which needs to run as root because it’s listening on port 80).
Obviously the real Heroku is doing far more than this toy application, but I hope it helps you create a mental model of what Heroku is doing and how things are connected.
There are plenty of important things I don’t have space to cover - DNS, HTTP/2, UDP - but I hope the resources below provide some useful pointers.
Useful resources
Set up your own virtual server (for free!) - this is super useful for getting familiar with server and deployment.
High Performance Browser Networking - the primer chapters are very useful, though don’t worry about actually implementing all of the optimisation suggestions.
Free Cisco networking certification - very in-depth but comprehensive, if you find this interesting.